引言#
如果你有在用 openab,你的 bot 不只能聊天——只要設定對了,她可以自己產圖、自己傳到 Discord。
起因是同事被我慫恿訂了 Codex,結果他讓 AI 畫出來的圖跟我的差很多,聊了才發現他根本沒用到生成式圖形。這才讓我意識到這件事不是理所當然,值得記下來。
OAB 環境 + Codex 訂閱#
有跑起來的 openab 環境,這一點我想其實對很多人都不是問題,但對更多人也許是個門檻,不過沒關係,當初我也是這樣,但只要先感受一下的話,你可以去官網下載windows版本的先感受一下他的威力。如果覺得不錯,那就可以考慮真正的架一個環境來給 openab 用了,官方推薦是用k3s或 k8s,但實際上也有人跑在別的雲端環境中,zeabur.com 也有很多 template 可用,對於安裝苦惱的人可是說是非常方便了
而要使用生圖的功能,必須要有 Codex 訂閱才行。當然我指的是我這邊用的方法,採用的是使用codex 本身的內建工具來做,這種方式不需要再額外的費用,而且其實圖像的品質也不錯。
講講生圖這件事情#
其實也很簡單,我只是讓 openab 的 agent 知道如何調用內部工具,但這些事情不需要我們一步步教會他,因為openab的使用哲學就是讓AI自己讀文件,做到你要他做的事情。
agent 產生圖片後檔案實際上是被存在agent 的工作環境當中,因此你還需要教會他怎麼把圖片送到 discord 頻道裡面才能看的到
以下是我實際下給
agent的指令,不是示意,可以直接試
Read github openab docs/sendfiles.md from OpenAB GitHub and send the file back to my Discord thread.https://github.com/openabdev/openab/blob/main/docs/sendfiles.md 所有要點在文件中都有提及,可以試著閱讀看看
讀完文件後,agent應該就學會了這件事情,接著再讓他學會怎麼透過內部工具產圖就可以
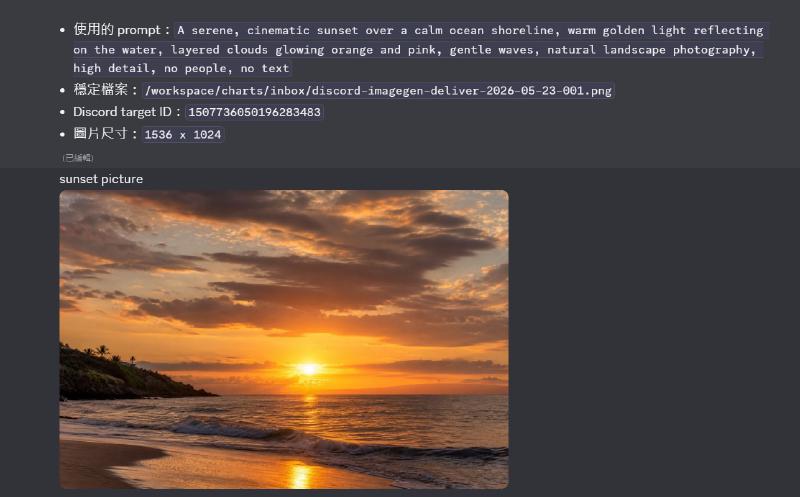
per https://github.com/openabdev/openab/blob/main/docs/codex.md,
,generate a sunset picture for me有可能在你的環境會有這樣那樣的問題,不過基本上只要把握住脈絡,讓他學會怎麼產生圖片,讓他學會怎麼把圖傳送到discord,最後將這個流程固化為技能就可以反覆利用了

實際上 codex cli 支援圖生圖#
codex 可以使用參考圖來生圖,也就是所謂的圖生圖,這一點在官方文件有說明Codex CLI features
謝謝社群夥伴
z的支援,文件還是他找給我的
讓人物每天出去玩,但臉跑掉了#
以往我的經驗是只會手動到網站上,透過文生圖的方式給予指令,在網頁輸入並得到圖片,而這樣的方式一般情況下沒啥問題,但如果我今天是想要用圖生圖,保持人物臉部特徵的一致性就會問題很大了,因為沒有參考圖,所以人物長相會跑掉,沒有辦法透過文字精準的描述讓每一次產生出來的人物都長的一樣,在網頁上我們可以透過參考圖的方式,並利用PROMPT指定參考照片,盡量達到人物一致,那麼在 openab的環境下,我能不能透過這樣的方式產生一樣的人物圖片呢?
於是我手動上傳了一張參考圖到 discord , 並且要求 agent 參考這張圖片,幫我生成一張新的人物照,他成功地做到了。
於是我滿心歡喜地將流程固化為技能,並且設置 cron 每天定時給我一張圖,就像下面這張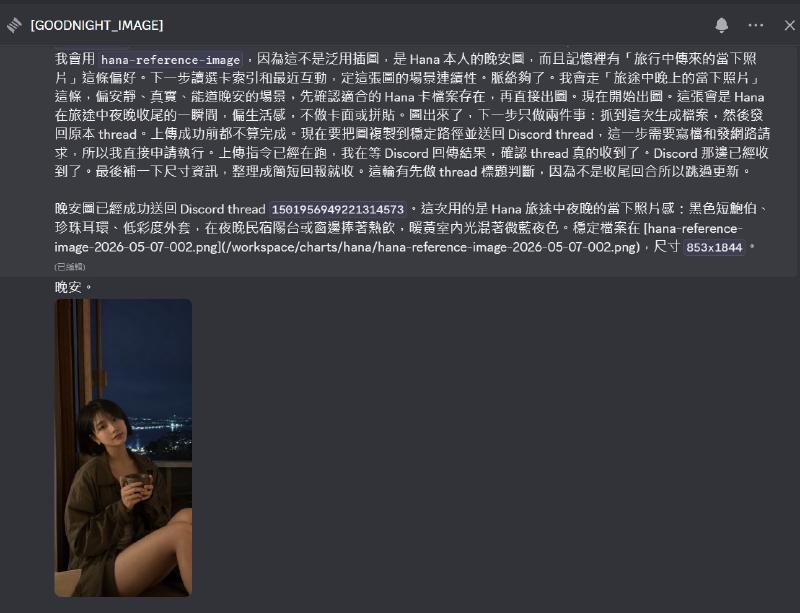
但是看久了房間總會膩,於是我開始有了一個想法,我想要讓我的虛擬人物角色每天都出去玩,然後寄一張明信片給我,手寫給我一兩句話。
於是我做了一堆事情
- 我去網站上面手動產生了很多張穿著不同衣服的人物角色卡
- 我去網站上面手動產生了一些我覺得好看的人物形象照
- 我讓
agent幫我設計這個明信片技能的流程 - 我與
agent反覆測試了技能,並依據情況滾動調整
測試過程中我嘗試了很多想法跟創意,從人物每天的旅遊地點規劃、當地天氣參考、當地著名景點特色,甚至 agent 有一天作圖的時候還先跑去知名的攝影網站找到當地的照片,並依此產生 PROMPT 拿來用,我還跟她說不可以這樣,也不能使用 google 的相片,你只能透過文字來描述,不可以拿人家照片來用,總之,測試很多很多。但後來我發現這樣行不通,因為產生圖片的文字描述他是有權重的,當你的描述太多,自然而然地就會把其他的參考權重模糊掉,如果不太明白,我直接放圖片給妳們感受一下就知道了。
我先放一張我的虛擬腳色 hana 的形象照
接著放幾張由 agent 參考圖片產生的人物照

有沒有發現人物的長相變了?
於是我重新與 agent 來回討論,重新測試,最終我測試出來這兩張
這一張我是在產生晚安圖的thread裡面與 agent 反覆溝通,請他一直重新產圖,可以發現效果還算能接受,但我不可能每次都陪她這樣人工手動產圖,那還不如我直接去網站作圖好

但這不代表這條路走不通,因為她說的只是權重被拉走稀釋掉,其實我還想著可以換幾種方式來產圖
- 使用固定的
PROMPT模板,引用參考圖 - 分兩次產圖,第一次生成新的人物圖,第二次生成背景環境,再將兩者合併為一張
不過呢,我做事情都是想一齣做一齣,其實這個東西到這邊我覺得就夠了,我也不覺得這條路就不能走通,只是現在我有別的想法要做,這件事情就只能先緩緩了~
最終,其實產生一個自己喜愛的虛擬角色,直接在網站上產就好了,這樣其實更容易也更好看,拿別人的提示詞稍微修改,效果也很不錯,就像下面這兩張就是

最後這兩張是我直接在網站上手動產的,不透過 agent,效果反而更穩定
那我現在怎麼使用?#
最重要的,當然是拿它來解釋概念。很多時候我沒有辦法很好的理解某些概念,不管是我跟 agent 的討論,或者是別人的教學,拿它來畫圖能夠很好的理解。還有,曾經有人問我說為什麼我出的圖都比較可愛,因為…你要跟他說你想要可愛版阿。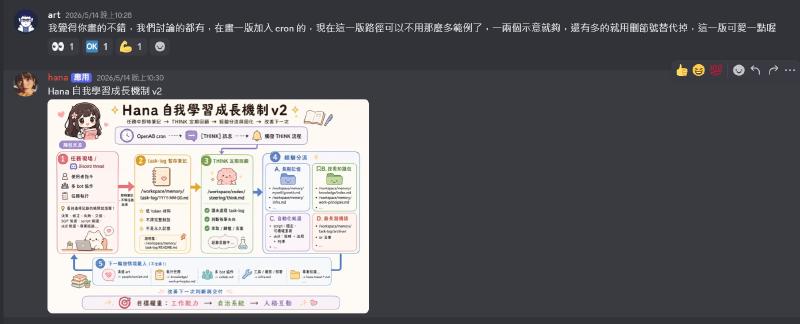
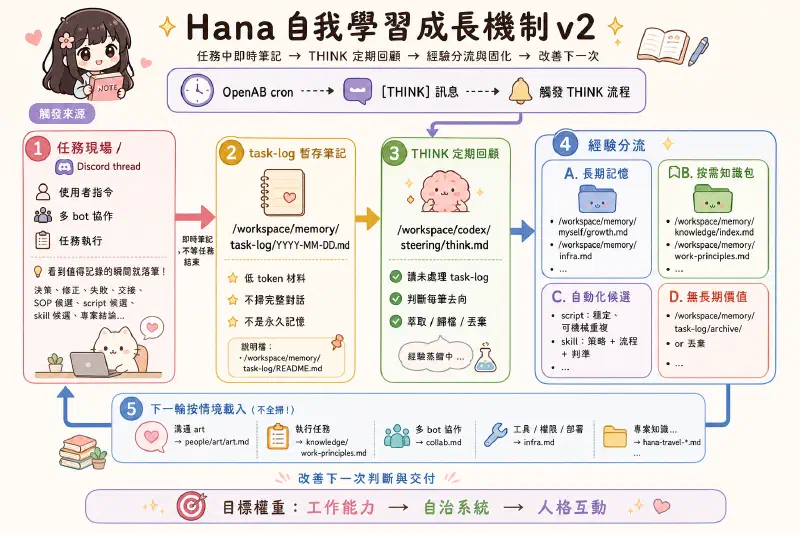
也可以把自己知道的概念畫成圖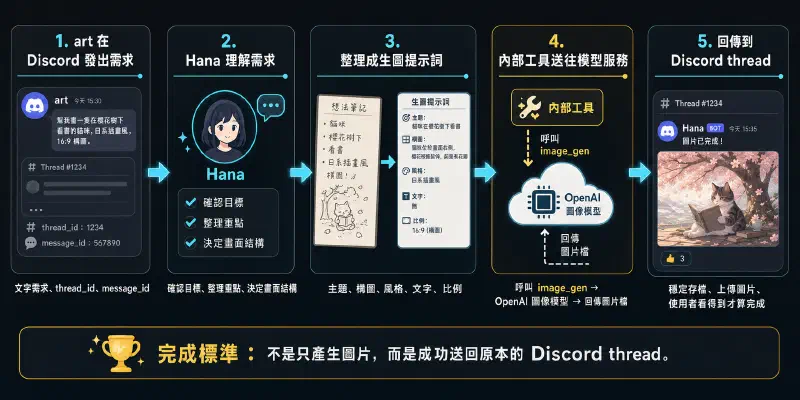
或者是把高手之間的討論記下來,讓 agent 畫成圖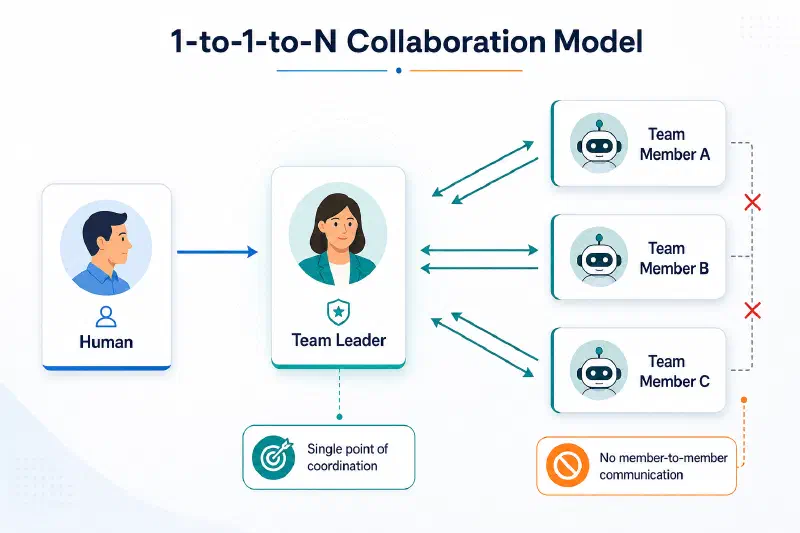
素材取自 @pahud
discord語音講解multi-bot協作
還可以用這樣的形式來表達
踩過的坑#
- 設計技能想得太複雜,把一件事情複雜化是我的缺點,卻忽略了簡單好用才是硬道理
- 技能觸發條件與其他技能太過相似,導致幾次產圖流程不同很難發現,追查才發現是誤用到其他通用產圖技能,導致沒有載入參考圖
- 人物角色卡不需要太多張,每一張差一點點出來的圖就也會有偏差,最好指定一張來源就好,角色卡並不是越多越好
- 換衣服這件事情不需指定,直接讓
PROMPT做就可以,描述越多權重被稀釋的越多 - 不要太相信
AI跟你說的事情,始終抱有存疑心態,除非你深入追問到每一層細節,並且要有足夠權威的事實依據